
- Home
- About
- Portfolio
Crush the Match – Medical School and Residency Platform
Food¢ense – Curbing Childhood Obesity and Food Waste
HealthStack – Shared and Jailed HIPAA Hosting $50
Marta Care – Let Us Help When You Can’t
MD Idea Lab – We Build Prototypes for Doctors
Nervcell – The Healthcare Web Browser
Patient Keto – Personalized Keto Medicine and Telehealth
SwipeChart – Rapid EMR Interface
Treatment Scores – Quantifying the Science of Medicine
Treatments – Diagnosed. Now What?
VIDRIO – Google Glass and EMR Interface
- Blog
- Contact
Category: Programming

Using Python to Parse HL7 and CCD Documents in Healthcare
By Stephen Fitzmeyer, MD
Python is a powerful programming language that can be used to parse and manipulate healthcare data in the HL7 and CCD formats. In this article, we will explore how to use Python to extract and process data from HL7 and CCD documents.
First, let’s start by understanding the structure of HL7 and CCD documents. HL7 messages are comprised of segments, which contain fields and subfields that represent different types of data. CCD documents, on the other hand, are based on the HL7 Clinical Document Architecture (CDA) standard and use XML to represent the data.
To parse HL7 messages in Python, we can use the hl7apy library, which is an open-source Python library for working with HL7 messages. Here’s an example of how to use hl7apy to extract patient demographic information from an HL7 message:
from hl7apy.parser import parse_message
# Parse the HL7 message
msg = parse_message(‘MSH|^~\&|HIS|BLG|LIS|BLG|20200528163415||ADT^A04|MSG0001|P|2.3||||||UNICODE’)
# Get the patient name
patient_name = msg.pid[5][0].value
# Get the patient date of birth
dob = msg.pid[7].value
# Get the patient sex
sex = msg.pid[8].value
# Print the patient information
print(“Patient Name: ” + patient_name)
print(“Date of Birth: ” + dob)
print(“Sex: ” + sex)
##########
In this example, we’re using the parse_message() method from the hl7apy library to parse the HL7 message. We then use the message object to extract the patient name, date of birth, and sex from the PID segment.
To parse CCD documents in Python, we can use the ElementTree library, which is included in the Python standard library. Here’s an example of how to use ElementTree to extract medication information from a CCD document:
import xml.etree.ElementTree as ET
# Parse the CCD document
tree = ET.parse(‘ccd.xml’)
# Get the medication section
medications = tree.findall(‘.//{urn:hl7-org:v3}section[@code=”10160-0″]/{urn:hl7-org:v3}entry/{urn:hl7-org:v3}substanceAdministration’)
# Print the medication information
for med in medications:
drug_name = med.find(‘{urn:hl7-org:v3}consumable/{urn:hl7-org:v3}manufacturedProduct/{urn:hl7-org:v3}manufacturedMaterial/{urn:hl7-org:v3}name/{urn:hl7-org:v3}part’).text
dosage = med.find(‘{urn:hl7-org:v3}doseQuantity/{urn:hl7-org:v3}value’).text
start_date = med.find(‘{urn:hl7-org:v3}effectiveTime/{urn:hl7-org:v3}low’).attrib[‘value’]
end_date = med.find(‘{urn:hl7-org:v3}effectiveTime/{urn:hl7-org:v3}high’).attrib[‘value’]
print(“Drug Name: ” + drug_name)
print(“Dosage: ” + dosage)
print(“Start Date: ” + start_date)
print(“End Date: ” + end_date)
##########
In this example, we’re using the findall() method from the ElementTree library to find all the medication sections in the CCD document. We then use the find() method to extract the drug name, dosage, start and end date for each medication and print out the results.
Using Python to parse HL7 and CCD documents can be very useful in healthcare applications. For example, we can use these techniques to extract and analyze data from electronic health records (EHRs) to identify patterns and trends in patient care and outcomes. This can help healthcare providers to improve the quality of care, reduce costs, and enhance patient safety.
In conclusion, Python is a powerful tool for parsing and manipulating healthcare data in the HL7 and CCD formats. By using Python to extract and process data from these documents, we can gain valuable insights into patient care and outcomes, which can help to improve healthcare delivery and patient outcomes.
Author: Stephen Fitzmeyer, M.D.
Physician Informaticist
Founder of Patient Keto
Founder of Warp Core Health
Founder of Jax Code Academy, jaxcode.com
Connect with Dr. Stephen Fitzmeyer:
Twitter: @PatientKeto
LinkedIn: linkedin.com/in/sfitzmeyer/
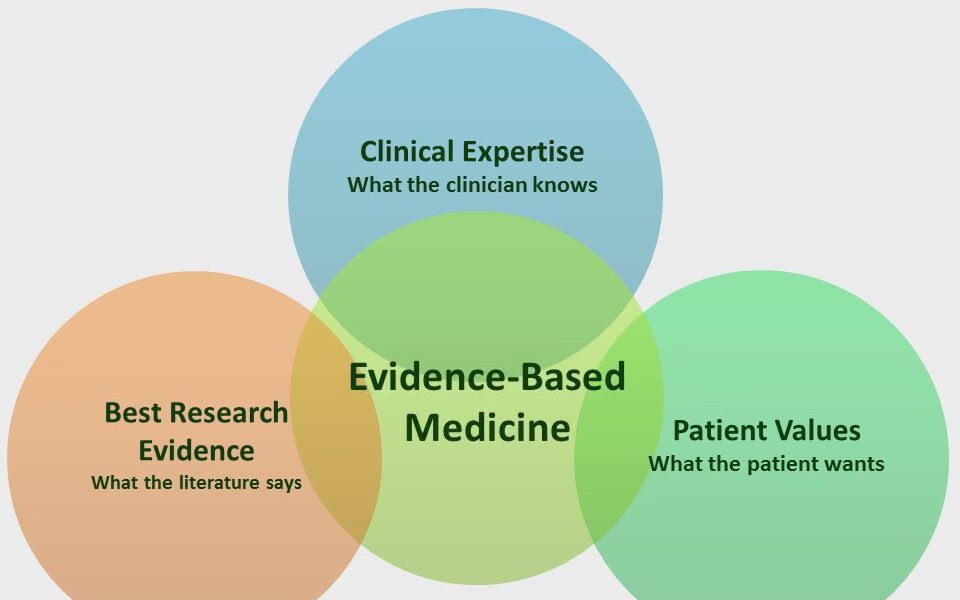
Coding Evidence-Based Medicine into Web-Based Applications
By Stephen Fitzmeyer, MD
Evidence-based medicine (EBM) is a medical approach that involves using the best available evidence to make informed clinical decisions. The goal of EBM is to improve the quality of patient care by integrating research evidence, clinical expertise, and patient preferences into clinical decision making. In recent years, there has been a growing interest in using technology to support EBM and help clinicians make evidence-based decisions. Web-based applications are a popular way to accomplish this goal.
Web-based applications that incorporate EBM can provide clinicians with easy access to the latest research evidence, as well as clinical practice guidelines and other relevant resources. These applications can help clinicians make informed decisions about diagnosis, treatment, and management of a wide range of medical conditions.
The process of building a web-based EBM application involves several steps. The first step is to identify the target audience and determine the specific clinical needs that the application will address. This may involve conducting a needs assessment and identifying gaps in current clinical practice.
The second step is to identify relevant EBM resources and integrate them into the application. This may involve using electronic databases, such as PubMed or Cochrane Library, to search for the latest research evidence. It may also involve incorporating clinical practice guidelines, systematic reviews, and other evidence-based resources into the application.
Once the relevant EBM resources have been identified, the next step is to design the application’s user interface. The application should be easy to navigate, intuitive to use, and provide users with relevant information at the appropriate time. The design of the application should be based on user-centered design principles, which involve actively involving users in the design process and incorporating their feedback into the final product.
After the application has been designed, the next step is to develop the application using web development languages and frameworks such as HTML, CSS, JavaScript, and React. The application may also incorporate server-side programming languages such as PHP or Python, and databases such as MongoDB or MySQL to store and retrieve data.
Finally, the application should be tested and validated to ensure that it is functioning as intended and providing accurate and reliable information to users. This may involve user testing, where the application is tested by actual users, as well as usability testing, where the application is tested for ease of use and effectiveness.
In conclusion, web-based applications that incorporate EBM can provide clinicians with easy access to the latest research evidence and clinical practice guidelines, helping them make informed decisions about patient care. The development of these applications involves identifying the target audience and their clinical needs, integrating relevant EBM resources, designing an intuitive user interface, developing the application using web development languages and frameworks, and testing and validating the application to ensure that it is effective and reliable. By following these steps, developers can build web-based EBM applications that improve patient care and support evidence-based decision making in clinical practice.
Author: Stephen Fitzmeyer, M.D.
Physician Informaticist
Founder of Patient Keto
Founder of Warp Core Health
Founder of Jax Code Academy, jaxcode.com
Connect with Dr. Stephen Fitzmeyer:
Twitter: @PatientKeto
LinkedIn: linkedin.com/in/sfitzmeyer/
A Step-by-Step Guide to Coding a Personal Health Record
By Stephen Fitzmeyer, MD
A personal health record (PHR) is a digital tool that allows individuals to maintain and manage their health information in a secure and accessible way. PHRs can be created by healthcare providers or individuals themselves. In this article, we will discuss the steps to coding a PHR.
Step 1: Define the data model
The first step in coding a PHR is to define the data model. This involves identifying the different types of health information that will be stored in the PHR. The data model should include the patient’s demographic information, medical history, medications, allergies, immunizations, laboratory results, and other relevant health information. The data model should also define the relationships between different types of information.
Step 2: Choose a programming language
The next step is to choose a programming language for coding the PHR. There are many programming languages to choose from, including Java, Python, Ruby, and PHP. The choice of programming language will depend on the developer’s expertise, the features required, and the platform on which the PHR will be deployed.
Step 3: Design the user interface
The user interface (UI) is the part of the PHR that patients will interact with. The UI should be intuitive and easy to use. It should allow patients to input and view their health information, as well as update and share it with healthcare providers. The design of the UI should be based on best practices for user experience (UX) and accessibility.
Step 4: Develop the back-end
The back-end of the PHR is the part of the application that handles the storage and retrieval of data. The back-end should be designed to ensure the security and confidentiality of patient health information. It should also be scalable and efficient, to handle large volumes of data and support future expansion.
Step 5: Integrate with other systems
PHRs need to integrate with other healthcare systems, such as electronic health records (EHRs), health information exchanges (HIEs), and patient portals. Integration with these systems will allow patients to access their health information from different sources, and share it with healthcare providers as needed.
Step 6: Test and deploy
Before deploying the PHR, it is essential to test it thoroughly to ensure that it works as expected and meets the needs of patients and healthcare providers. Testing should include functionality testing, performance testing, security testing, and user acceptance testing. Once testing is complete, the PHR can be deployed on a secure platform, such as a cloud-based server or a local server.
Conclusion
Coding a PHR requires careful planning and attention to detail. By following the steps outlined in this article, developers can create a PHR that is secure, scalable, and user-friendly. A well-designed PHR can empower patients to take control of their health information, improve healthcare outcomes, and support the delivery of personalized and coordinated healthcare services.
Author: Stephen Fitzmeyer, M.D.
Physician Informaticist
Founder of Patient Keto
Founder of Warp Core Health
Founder of Jax Code Academy, jaxcode.com
Connect with Dr. Stephen Fitzmeyer:
Twitter: @PatientKeto
LinkedIn: linkedin.com/in/sfitzmeyer/