
- Home
- About
- Portfolio
Crush the Match – Medical School and Residency Platform
Food¢ense – Curbing Childhood Obesity and Food Waste
HealthStack – Shared and Jailed HIPAA Hosting $50
Marta Care – Let Us Help When You Can’t
MD Idea Lab – We Build Prototypes for Doctors
Nervcell – The Healthcare Web Browser
Patient Keto – Personalized Keto Medicine and Telehealth
SwipeChart – Rapid EMR Interface
Treatment Scores – Quantifying the Science of Medicine
Treatments – Diagnosed. Now What?
VIDRIO – Google Glass and EMR Interface
- Blog
- Contact
Category: Machine Learning

Using Python to Parse HL7 and CCD Documents in Healthcare
By Stephen Fitzmeyer, MD
Python is a powerful programming language that can be used to parse and manipulate healthcare data in the HL7 and CCD formats. In this article, we will explore how to use Python to extract and process data from HL7 and CCD documents.
First, let’s start by understanding the structure of HL7 and CCD documents. HL7 messages are comprised of segments, which contain fields and subfields that represent different types of data. CCD documents, on the other hand, are based on the HL7 Clinical Document Architecture (CDA) standard and use XML to represent the data.
To parse HL7 messages in Python, we can use the hl7apy library, which is an open-source Python library for working with HL7 messages. Here’s an example of how to use hl7apy to extract patient demographic information from an HL7 message:
from hl7apy.parser import parse_message
# Parse the HL7 message
msg = parse_message(‘MSH|^~\&|HIS|BLG|LIS|BLG|20200528163415||ADT^A04|MSG0001|P|2.3||||||UNICODE’)
# Get the patient name
patient_name = msg.pid[5][0].value
# Get the patient date of birth
dob = msg.pid[7].value
# Get the patient sex
sex = msg.pid[8].value
# Print the patient information
print(“Patient Name: ” + patient_name)
print(“Date of Birth: ” + dob)
print(“Sex: ” + sex)
##########
In this example, we’re using the parse_message() method from the hl7apy library to parse the HL7 message. We then use the message object to extract the patient name, date of birth, and sex from the PID segment.
To parse CCD documents in Python, we can use the ElementTree library, which is included in the Python standard library. Here’s an example of how to use ElementTree to extract medication information from a CCD document:
import xml.etree.ElementTree as ET
# Parse the CCD document
tree = ET.parse(‘ccd.xml’)
# Get the medication section
medications = tree.findall(‘.//{urn:hl7-org:v3}section[@code=”10160-0″]/{urn:hl7-org:v3}entry/{urn:hl7-org:v3}substanceAdministration’)
# Print the medication information
for med in medications:
drug_name = med.find(‘{urn:hl7-org:v3}consumable/{urn:hl7-org:v3}manufacturedProduct/{urn:hl7-org:v3}manufacturedMaterial/{urn:hl7-org:v3}name/{urn:hl7-org:v3}part’).text
dosage = med.find(‘{urn:hl7-org:v3}doseQuantity/{urn:hl7-org:v3}value’).text
start_date = med.find(‘{urn:hl7-org:v3}effectiveTime/{urn:hl7-org:v3}low’).attrib[‘value’]
end_date = med.find(‘{urn:hl7-org:v3}effectiveTime/{urn:hl7-org:v3}high’).attrib[‘value’]
print(“Drug Name: ” + drug_name)
print(“Dosage: ” + dosage)
print(“Start Date: ” + start_date)
print(“End Date: ” + end_date)
##########
In this example, we’re using the findall() method from the ElementTree library to find all the medication sections in the CCD document. We then use the find() method to extract the drug name, dosage, start and end date for each medication and print out the results.
Using Python to parse HL7 and CCD documents can be very useful in healthcare applications. For example, we can use these techniques to extract and analyze data from electronic health records (EHRs) to identify patterns and trends in patient care and outcomes. This can help healthcare providers to improve the quality of care, reduce costs, and enhance patient safety.
In conclusion, Python is a powerful tool for parsing and manipulating healthcare data in the HL7 and CCD formats. By using Python to extract and process data from these documents, we can gain valuable insights into patient care and outcomes, which can help to improve healthcare delivery and patient outcomes.
Author: Stephen Fitzmeyer, M.D.
Physician Informaticist
Founder of Patient Keto
Founder of Warp Core Health
Founder of Jax Code Academy, jaxcode.com
Connect with Dr. Stephen Fitzmeyer:
Twitter: @PatientKeto
LinkedIn: linkedin.com/in/sfitzmeyer/

What is Health Information Technology? Exploring the Benefits and Challenges of HIT
By Stephen Fitzmeyer, MD
Healthcare has been rapidly evolving with the advent of new technologies. Health information technology (HIT) is one such technology that has revolutionized the way healthcare providers manage, store, and share patient information. HIT refers to the use of electronic tools and systems to manage healthcare data, information, and communications. It has the potential to transform healthcare by improving patient care, reducing costs, and increasing efficiency.
The benefits of HIT are numerous. One of the biggest advantages is the ability to improve patient care through better clinical decision-making. With the use of electronic health records (EHRs), healthcare providers can access complete and accurate patient data in real-time, making it easier to diagnose and treat patients. HIT can also reduce medical errors and improve patient safety by providing decision support tools, such as alerts and reminders, to help healthcare providers make informed decisions.
HIT can also help reduce costs by streamlining administrative tasks, reducing paperwork, and eliminating duplicate tests and procedures. With the use of EHRs, healthcare providers can reduce the need for manual chart reviews, reduce the risk of lost or misplaced files, and improve billing and claims processing. Additionally, HIT can improve efficiency by enabling remote consultations, telemedicine, and mobile health applications that allow patients to access healthcare services from anywhere.
However, there are also challenges associated with HIT. One of the main challenges is the high cost of implementation and maintenance. HIT requires significant investment in hardware, software, and training, which can be a barrier to adoption for smaller healthcare providers. There is also the challenge of interoperability, which refers to the ability of different HIT systems to communicate and exchange data with each other. Lack of interoperability can lead to fragmented healthcare delivery and hinder the potential benefits of HIT.
Another challenge is the issue of data security and privacy. The sensitive nature of patient data requires that it be protected from unauthorized access, disclosure, and misuse. HIT systems must comply with various data privacy and security regulations, such as the Health Insurance Portability and Accountability Act (HIPAA) and the General Data Protection Regulation (GDPR), to ensure that patient information is kept confidential and secure.
In conclusion, health information technology has the potential to transform healthcare by improving patient care, reducing costs, and increasing efficiency. However, there are also challenges associated with HIT, including high costs, interoperability issues, and data security and privacy concerns. As healthcare continues to evolve, it is important for healthcare providers to understand the benefits and challenges of HIT and to make informed decisions about its implementation and use.
Author: Stephen Fitzmeyer, M.D.
Physician Informaticist
Founder of Patient Keto
Founder of Warp Core Health
Founder of Jax Code Academy, jaxcode.com
Connect with Dr. Stephen Fitzmeyer:
Twitter: @PatientKeto
LinkedIn: linkedin.com/in/sfitzmeyer/
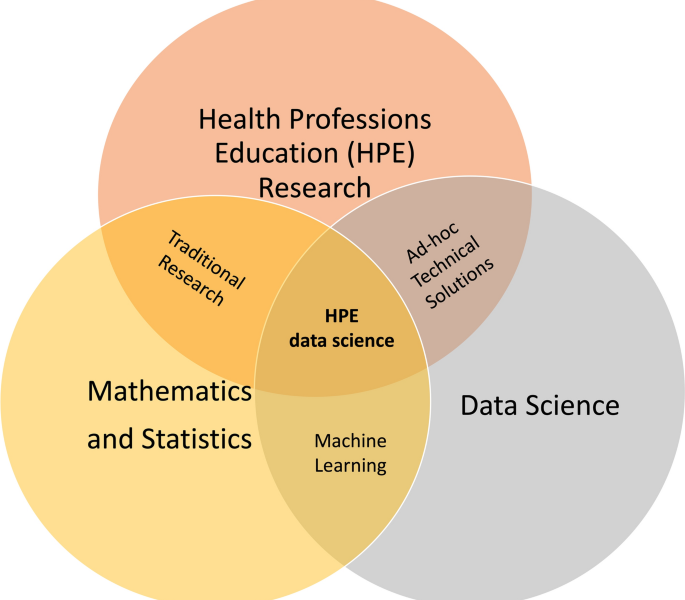
The Intersection of Data Science, Artificial Intelligence, Epidemiology, and Machine Learning in Healthcare
By Stephen Fitzmeyer, MD
The healthcare industry is facing unprecedented challenges due to rising costs, aging populations, and the increasing prevalence of chronic diseases. However, the integration of data science, artificial intelligence (AI), epidemiology, and machine learning (ML) is providing new opportunities to improve outcomes and reduce costs.
Data science is the study of data using various computational and statistical methods to extract meaningful insights. In healthcare, data science is being used to analyze large and complex data sets to identify patterns, correlations, and other trends. These insights can help healthcare providers make more informed decisions, improve patient outcomes, and reduce costs.
AI involves the development of computer algorithms and systems that can perform tasks that typically require human intelligence, such as perception, reasoning, and learning. In healthcare, AI is being used to develop diagnostic tools, predict disease progression, and improve patient care. For example, AI-powered systems can analyze medical images, such as X-rays and MRIs, to detect abnormalities and assist in diagnosis.
Epidemiology is the study of how diseases spread and how they can be controlled. In healthcare, epidemiology is used to track and monitor the occurrence of diseases, identify risk factors, and develop prevention strategies. For example, epidemiologists can use data to track the spread of infectious diseases and develop interventions to control outbreaks.
Machine learning is a subset of AI that involves the development of algorithms that can learn and improve from data. In healthcare, ML is being used to identify patterns and correlations in patient data, predict outcomes, and improve clinical decision making. For example, ML can be used to analyze electronic health records (EHRs) to identify patients at high risk of developing complications or readmission to the hospital.
The integration of data science, AI, epidemiology, and ML is creating new opportunities to improve outcomes and reduce costs in healthcare. For example, by combining data from multiple sources, such as EHRs, claims data, and social determinants of health, healthcare providers can gain a more comprehensive understanding of patients’ health and develop personalized treatment plans. By using AI-powered diagnostic tools, providers can make more accurate diagnoses, leading to more effective treatments and improved outcomes. By using ML to analyze patient data, providers can predict patient outcomes and intervene early, reducing the likelihood of readmission and complications.
In conclusion, the integration of data science, AI, epidemiology, and ML is revolutionizing healthcare by providing new opportunities to improve outcomes and reduce costs. By using these technologies to analyze patient data, healthcare providers can develop more personalized treatment plans, make more accurate diagnoses, and predict patient outcomes. As these technologies continue to evolve, we can expect to see even greater improvements in healthcare outcomes and cost savings.
Author: Stephen Fitzmeyer, M.D.
Physician Informaticist
Founder of Patient Keto
Founder of Warp Core Health
Founder of Jax Code Academy, jaxcode.com
Connect with Dr. Stephen Fitzmeyer:
Twitter: @PatientKeto
LinkedIn: linkedin.com/in/sfitzmeyer/